

Table of Contents
Intro
Understanding data lakes on AWS can be overwhelming with the variety of services and complex integration paths. This article offers one practical scenario of how some of these services can be interconnected. We will walk through the following steps:
- Capturing Real-Time Data: Utilizing the News API to gather the latest news.
- Data Streaming: We’ll build a simple C# app to push the news data into a Kinesis Firehose stream.
- Data Querying: We’ll explore the stored data in S3 directly with Athena.
- ETL: We’ll see how to create an ETL process via a Glue Job to load the data into a relational database – a MySQL RDS instance.
Here is a diagram representing the end-to-end process:

Let’s get started!
News API Overview
News API is a simple HTTP REST API for retrieving news articles from all over the web. It’s a powerful tool for developers looking to tap into a diverse range of news sources, including major global news outlets and smaller regional publishers.
Getting Started with News API
To start using the API, you must first sign up for an API key on their website. This key will authenticate your requests.
Sample API Call
The focus of this article is not to explore the News API in detail, so here’s just a brief overview of the API contract. You need to send an HTTP GET call to a URL like this:
https://newsapi.org/v2/everything?sources=bbc-news
The query parameter sources=bbc-news
It’s important to provide your API key in the X-Api-Key request header.
In the screenshot below, you can see a sample request with the JSON response returned by the API. The response data includes various pieces of information such as the source, author, title, description, and URL of the articles:

Setting Up the Glue Data Catalogue
The Glue Data Catalogue acts as a metadata repository for our AWS services. For example, it contains the data schema the Firehose stream needs to convert JSON data to Parquet and later for the Glue Job to extract the data that will be loaded in MySQL. We’ll also use the Glue Catalogue to query the data with Athena.
Creating the Glue Database
Create a new Glue Database named news-db via the AWS Glue dashboard.

Creating the S3 Bucket
Before creating the Firehose stream, we need to set up an Amazon S3 bucket, which will be the destination for the streaming data. Just go to the S3 dashboard and create a bucket like so:

Defining the Glue Table and Schema
Next, create a news table in the news-db Glue database:

Set S3 as data store, select the bucket we created above, and Parquet data format:

Click Next to provide the Parquet schema:

For this demo, I will set the schema by inserting the following JSON that’s available on GitHub:

The schema contains a subset of fields from the News API response format.
Configuring the Firehose Stream
After setting up our Glue Data Catalogue, the next step is configuring the Kinesis Firehose stream, which will be our data ingestion system. This stream will be designed to accept direct PUT requests from our C# application.
Creating the Firehose Stream
Go to the Kinesis Firehose dashboard to create the Firehose delivery stream.
Select Direct PUT as Source, Amazon S3 as Destination, and set the stream name.

Make sure you enable record transformation to Parquet, which will require specifying the previously defined Glue table:

As recommended, select the same S3 bucket in the Destination settings that we used when creating the Glue table:

Finally, hit the “Create Delivery Stream” button.
C# Integration with News API and Firehose
In this section, we will explore the C# code for fetching data from the News API and pushing the entries into Kinesis Firehose to load the data into S3. The full source code is provided in our GitHub repository, but let’s review some of the main pieces.
Fetch Articles from News API
Retrieving the news articles is fairly simple using the News API SDK. Here is a small snippet that demonstrates how to do that:

Here, we are retrieving articles posted in the last five days, filtering by publishers, and sorting by the PublishedAt field.
Streaming Data to Kinesis Firehose
Next, we’re pushing the articles to the Firehose stream in JSON format (recall that we configured Firehose to convert the data format from JSON to Parquet). Here is the C# code for it:

Running the App
Before running the app, assign your API key to the apiKey constant.
Once the execution is completed, you should see the output in the console similar to the following:

Reviewing the Data in the S3 Bucket
After Firehose processes the data, it is automatically saved into the configured S3 bucket. The data files are organized by date and time:

Exploring the Data with Athena
With the data loaded in S3 and stored in Parquet format, we can now utilize Amazon Athena to run queries against our dataset, as shown in the screenshot below:

Networking
Before we can create our AWS Glue ETL job that will load the data into MySQL, we need several networking components to ensure connectivity within our AWS environment. Let’s walk through each of them.
Creating a VPC
It’s always a good idea to create a separate VPC to keep your networking environments isolated.
So, let’s create one.
Assign a name such as news-vpc, and define a CIDR range for it like 10.0.0.0/24:

Creating Subnets
Our RDS database will require at least two subnets in two different AZs for high-availability deployment, so let’s create those with their CIDR ranges:

news-subnet-1 CIDR – 10.0.0.0/25
news-subnet-2 CIDR – 10.0.0.128/25
Again, make sure you select different Availability Zones for the two subnets.
Creating a Route Table
The Glue Job that we’ll create later will require private connectivity to S3. For that, we’ll need to create a VPC Gateway and add a route to it from the Route Table.
We’ll set up the VPC Gateway in the next section, but let’s have the Route Table ready first:

Make sure to associate the subnets we created in the previous section with the route table.

Setting Up an S3 VPC Gateway
To allow AWS Glue to access S3 data securely within our VPC without using public internet routes, we set up an S3 VPC Gateway, also known as a VPC Endpoint for Amazon S3.
A VPC Endpoint enables you to privately connect your VPC to supported AWS services powered by AWS PrivateLink without needing an Internet Gateway, NAT device, VPN connection, or AWS Direct Connect connection.
To create the endpoint, from the VPC dashboard, go to “Endpoints” and click “Create Endpoint”.
- Set a name to the endpoint like
news-vpc-s3-endpoint. - From “Services”, select the
com.amazonaws.<region>.s3service name. - Select the
news-vpcVPC. - Select the
news-vpc-rtRoute Table.


Let’s ensure the route table has a new route pointing to the new S3 VPC Endpoint.
In the screenshot below, you’ll also see a route to an Internet Gateway, making the subnets public. The only reason for this is that I will be using an EC2 instance as a bastion host to connect to the MySQL database, so I need it publicly available for SSH access. This is done not to overcomplicate the demo. In a typical deployment, the RDS subnets will stay private, and the jump/bastion host will be deployed in a separate public subnet.

Configuring Security Groups for AWS Glue and RDS
For our AWS Glue Job and RDS database, we need to create a security group that allows AWS Glue to access the RDS database that we’ll create later. This security group will be assigned both to the Glue Job and the RDS instance, allowing traffic from itself, a pattern known as a “self-referencing security group.” This pattern is common for allowing instances within the same security group to communicate with each other.
Also, I’ll allow inbound traffic from my EC2 bastion host. Again, this is for demo purposes, and you might have a different setup if you’re connecting to your RDS instance through some other means.
Here is a screenshot of the Security Group configuration:
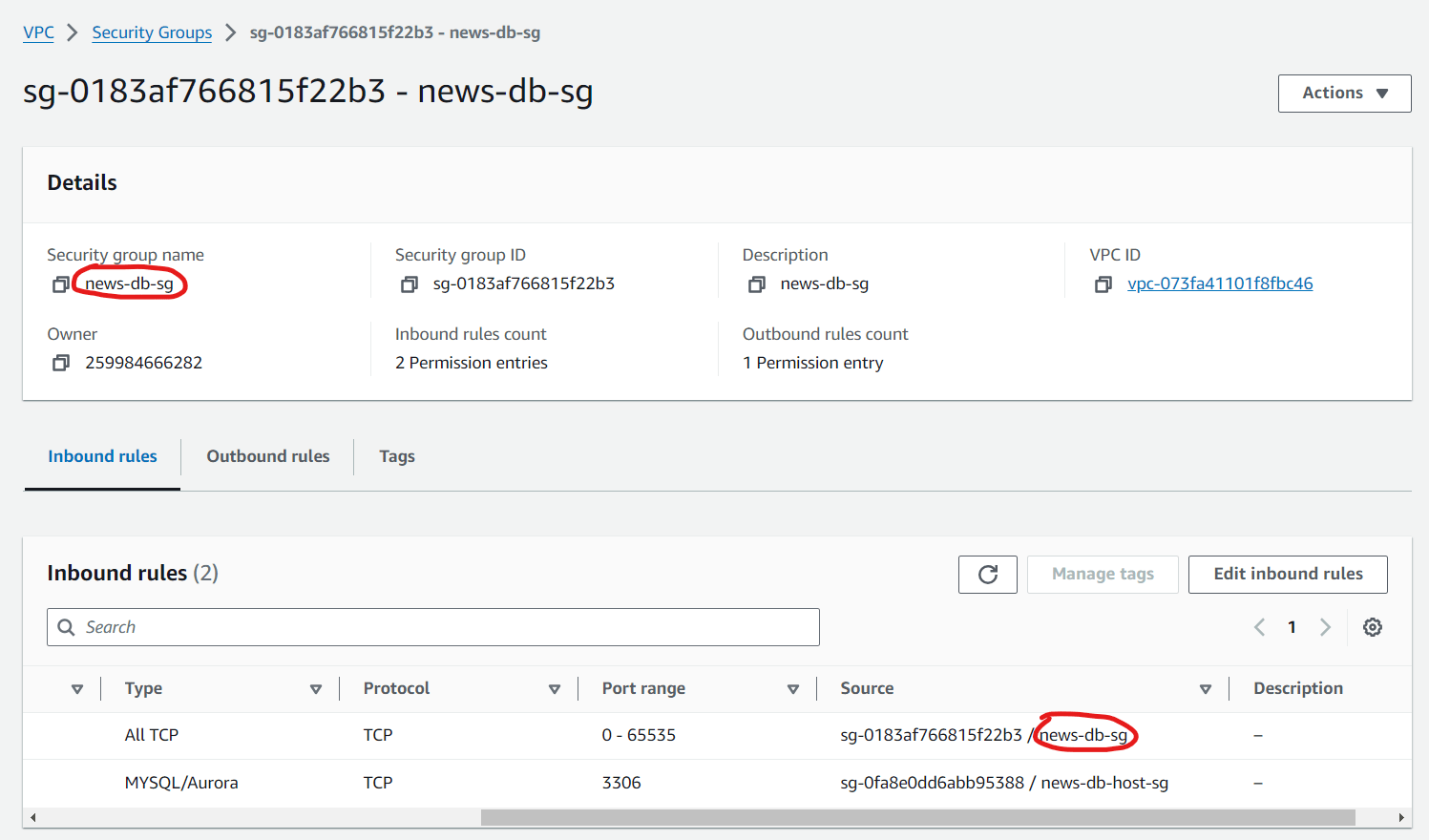
Notice the so-called “self-referencing rule” where news-db-sg allows inbound traffic from itself.
MySQL RDS Setup
It’s time to set up our MySQL RDS instance.
Creating a Subnet Group
First, we need to create an RDS Subnet Group. This group will contain the subnets we created previously. Let’s call it news-db-subnet-group.


Launching the MySQL Instance
Go to the RDS Dashboard and create a new MySQL instance.
Select MySQL DB engine:


Set the instance name and credentials:

Select the lowest cost instance type and default storage allocation:

In the connectivity section, make sure you select the news-vpc VPC and the subnet group and security group we’ve prepared:

Create the database and wait until it gets initialized.
Creating the news_db Database
Connect to the MySQL instance. For that, I’m using a command line mysql client:
mysql -h news-db.cycdqdcy75te.us-east-1.rds.amazonaws.com -P 3306 -u admin -p
Next, create the news_db database:

Setting Up the AWS Glue Job
We need to set up a few Glue components and permissions before creating and running the Job.
Creating the IAM Role for AWS Glue
First, we must create an IAM role with appropriate policies that the Glue Job needs to run properly.
Go to the IAM Dashboard and start creating a role. Select Glue as a service:

This would allow the Glue service to “assume” the role.
Let’s give it a name likeNewsDBGlueRole and attach the following policies:
- AmazonS3FullAccess: Access to S3 is needed so the Job can read and write to the buckets where the actual data is stored as well as for storing logs, metadata, etc…
Note: I took a shortcut here by adding an S3 admin policy to the role. This is generally way too permissive and doesn’t follow the “least privilege” security standard. When setting this up for production, make sure to investigate what would be the most restrictive set of S3 access policies that would still allow the Glue Job to execute properly. - AWSGlueServiceRole: This grants permissions for AWS Glue to access the resources it needs for ETL jobs.

Configuring and Verifying the AWS Glue Connection
Next, let’s set up a new Glue Connection called news-db-connection.
In the “Connections” section of the Glue dashboard, click “Create Connection”:

This connection will be used by the Job to connect to the RDS database. We’ll need to specify the connection details such as the database endpoint, port, and security group. We will use JDBC as the connector type.


Set a name news-db-connection; we’ll reference this later when creating the job.
You can test the connection to verify it’s configured properly:



Creating the Glue Job
Let’s create the actual Glue Job to load the data into MySQL.
Go to the Glue dashboard and start creating a new Glue Job. For this tutorial, we’ll be using the Script editor:

Select Spark as the engine:
Next, provide the Python script for the Job. You can check the full source on GitHub and directly copy it to the Script window:

The code itself is pretty simple and self-explanatory. It will extract data from the designated source, transform it according to the specified rules—such as remapping some fields—and finally load the transformed data into the MySQL database.
Next, in the “Job details” tab, specify the NewsDBGlueRole IAM role and select Spark as the job type. For scripting, we’ll use Python 3, which is compatible with Glue version 4.0.

Also, in the Advanced properties, you should select the previously created Glue Connection:

Hit the Save button to create the job.
Running the Job
To execute the job, just click the Run button:

You should get a message that the job has started:

If you go to the list of Jobs, it should be in Running state:

After a while, it should move to Succeeded.
Review data loaded in MySQL
Let’s now confirm that the data has been correctly loaded into our news_db database in MySQL:

Summary
This article provided a step-by-step guide to building a sample Data Lake on AWS, demonstrating the integration of various services. We started with a C# app to load data from News API into a Firegate stream. Then, we showcased how to query the data stored in S3 with Athena. After that, we configured and ran an ETL process using AWS Glue to load the data into a MySQL RDS instance.
Thanks for reading, and see you next time!




